Structured Qualitative Reporting from Public Discussion Data
Objective
Build a structured reporting system that converts fragmented public Reddit discussion about WGU courses into standardized, queryable issue summaries under explicit dataset constraints.
The focus is controlled dataset definition, validation, and deterministic reporting outputs, not predictive modeling or institutional evaluation.
Dataset Context
- ~27,000 Reddit posts initially collected
- 1,103 posts retained after rule-based filtering
- 242 distinct courses represented
- 51 WGU-related subreddits
- Filtered using a rule-based negative sentiment threshold to define the reporting corpus
- Exactly one identifiable course reference per post
Counts represent posts, not students.
A frozen dataset snapshot is used throughout the workflow. No live refresh occurs.
Structure & Reporting Architecture
The workflow follows a structured reporting design with clearly separated stages.
1. Frozen Intake Layer
- Public Reddit posts stored locally.
- Explicit inclusion rules applied.
- Resulting corpus treated as immutable for all downstream reporting.
2. Structured Classification & Field Definition
- Posts classified as containing course-side issues or not.
- Structured fields extracted under defined schemas.
- Parsing and schema errors preserved and logged.
- Outputs stored as saved reporting artifacts.
3. Within-Course Aggregation
- Issue posts grouped into recurring patterns per course.
- Traceability to individual posts maintained.
4. Cross-Course Category Alignment
- Course-level clusters aligned into shared issue categories.
- Enables standardized cross-course comparison using consistent reporting definitions.
5. Deterministic Reporting Layer
- Final reporting tables generated exclusively from stored outputs.
- Static snapshot site built from precomputed data.
- No runtime joins, aggregation, or inference in the presentation layer.
Transformation and presentation are strictly separated.
Reporting Outputs
Executive Summary View
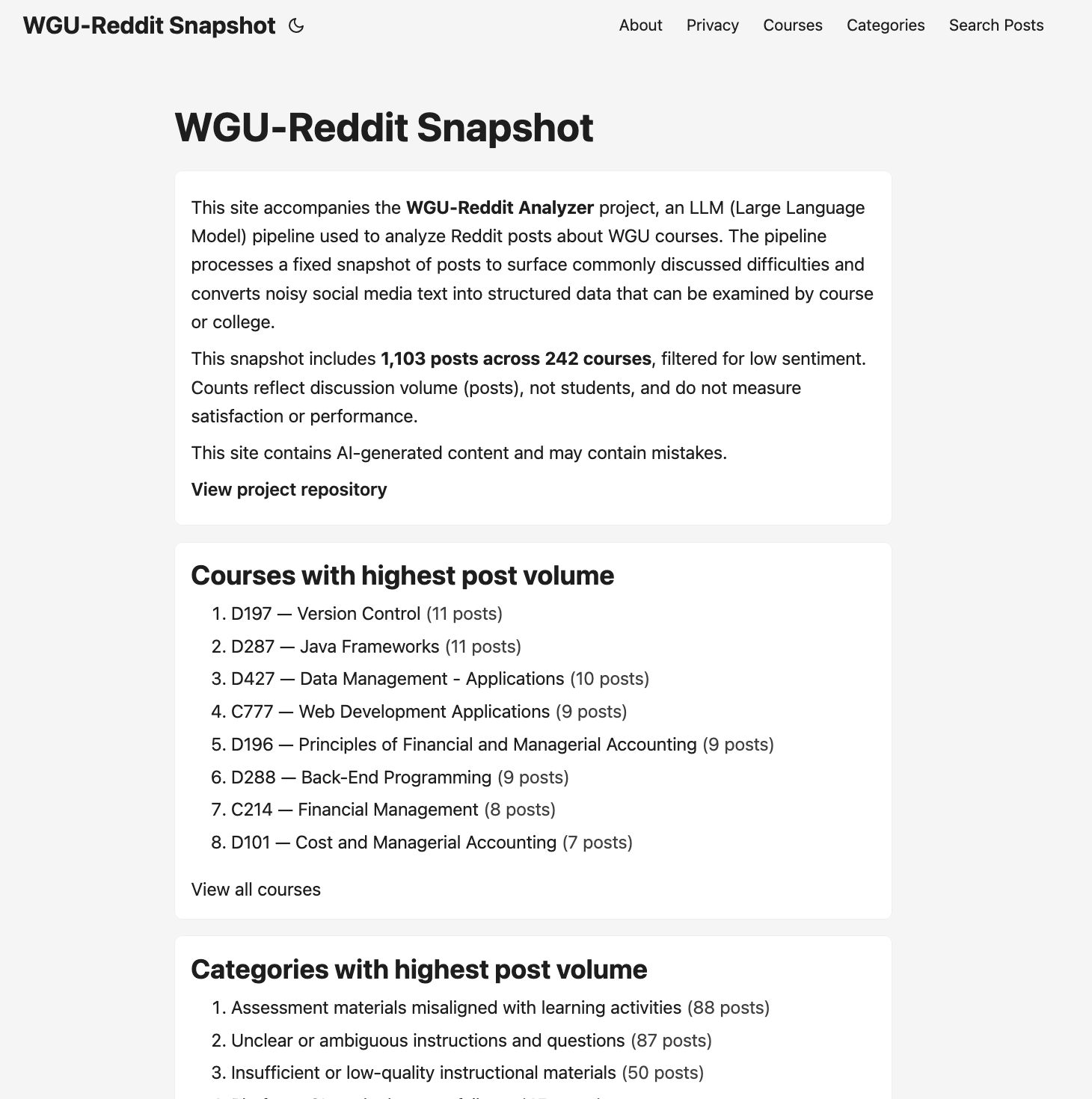
The homepage surfaces:
- Total post and course counts
- Courses with highest discussion volume
- Categories with highest post volume
- Explicit denominator disclaimers
All figures are precomputed and stable.
Course-Level Drill-Down

Each course page includes:
- Negative-sentiment post count
- Recurring issue patterns
- Category-aligned themes
- Supporting post excerpts
- Links to original public posts
This structure allows movement from aggregate counts to traceable source examples.
Cross-Course Category Alignment

Category pages display:
- Total posts
- Number of affected courses
- Cluster counts
- College distribution
This supports consistent, cross-course issue tracking under shared definitions.
Validation & Governance Controls
The following controls govern dataset construction, transformation, and final reporting outputs:
- Frozen corpus used across all stages.
- Explicit filtering criteria documented.
- Schema validation applied to structured fields.
- Saved outputs retained at each reporting stage.
- Deterministic reporting views built only from stored data.
- Clear separation between analysis and presentation.
- Public data only; usernames removed.
Extraction logic was validated prior to finalizing reporting outputs. Validation documentation remains available in the repository.
Validation supports reporting reliability but does not define reporting scope.
Reporting Highlights (Snapshot Basis)
Within the published snapshot:
- Assessment misalignment and ambiguous instructions are the highest-volume cross-course categories.
- Issue patterns frequently repeat within courses rather than appearing as isolated posts.
- Cross-course category alignment reveals recurring structural themes across multiple colleges.
All highlights reflect discussion volume only.
No institutional performance claims are made.
Limits & Interpretation Boundaries
- Public Reddit posts only.
- Not representative of the full student population.
- Counts represent posts, not students.
- Single-course requirement narrows scope.
- Sentiment used solely as a corpus gating rule.
- No causal inference or course-quality evaluation.
Unobserved discussion is treated as non-inferable.
What This Demonstrates
- Structured transformation of informal qualitative data into standardized reporting views.
- Governance-forward dataset construction under fixed inclusion rules.
- Explicit reporting grain prior to aggregation.
- Cross-stage validation and traceable outputs.
- Deterministic, inspection-ready reporting architecture.
- Static interface decoupled from transformation logic.
The result is a static, auditable reporting interface designed to support structured review of recurring course-level feedback patterns.
Links
Snapshot Site: https://wgudataninja.github.io/WGU-Reddit-Feedback-Analyzer/
Repository: https://github.com/wguDataNinja/WGU-Reddit-Feedback-Analyzer/